When authoring OCI Artifacts, the question of whether to put interesting information into annotations or a config object often comes up. Josh (maintainer of Chart Museum, ORAS and many other great OSS projects) was asking such a question here for Helm 3 charts stored in registries.
As we make progress with the OCI Artifacts repository, we’ll have a better place for this information, but lets iterate a bit here to form some thoughts.
Annotations for Search
Annotations are generally easy, free form name/value pairs. They are directly exposed in the manifest and can be easily parsed by a reader that wants to curl them, or by the registry that parses the manifest.
{
"schemaVersion": 2,
"config": {
"mediaType": "application/vnd.cncf.helm.config.v1+json",
"digest": "sha256:ca3d163bab055381827226140568f3bef7eaac187cebd76878e0b63e9e442356",
"size": 3,
"annotations": {
"apiVersion": "v1",
"appVersion": "5.2.2",
"description": "Web publishing platform for building blogs and websites.",
"home": "http://www.wordpress.com/",
"name": "wordpress",
"version": "7.0.1"
}
The most obvious value (to me) is a registry could use these values in search results. While registries don’t yet have a generalized search api, this is another effort we’re hoping to make more progress on. See this hackmd topic here: Cloud Native Artifact Search Requirements
A user could search for charts named wordpressregSearch demo42.azurecr.io name="wordpress", apiVersion="v1"
The key point is annotations are valuable as free-form data. The question is about visibility of the data. Does the info you want to expose need to be visible to generalized registry tooling? Or, is it specific to your artifact?
Config for Artifact Specific Details
The other option is using the config.json object to store details of the artifact. The mediaType of the config.json is used to identify the artifact type. While the config file can be null, it can also contain details that only the artifact tooling actually cares about.
For most artifact types, registries won’t want or need to parse these config objects. The config object would be used by the artifact tooling, and keep it’s details internal. For some types, registry authors may parse the config object. For instance, registry implementations parse the OCI image config to find the platform or architecture to help users understand if the image:tag is linux, windows or a multi-arch tag.
As yourself: does the information require more structure, and is it intended for artifact specific tooling?
Balancing Config and Annotations
While it’s up to each artifact author, there’s a question of guidance and how should these be used.
If the information is intended for the artifact specific tooling, I’d suggest using a custom config object is likely the way to go. It allows any structure the artifact tooling desires, including nested objects. The artifact must define a versioned schema of the config object, so others can parse the config, but the benefit here is internal information is kept internal. In the Artifact Config Schema Validation PR, I talk about creating an optional schema for an artifact, and publishing the schema with the artifact definition.
If the information is useful to generalized tooling around a registry, annotations are likely a better solution. The search criteria is the most obvious as I’d suspect registries operators will index annotations for searching. However, as manifests are displayed in registry tooling, how much detail do you need, or want displayed?
Below is a screenshot of an early helm 3 chart pushed to the Azure Container Registry. The config.mediaType is used to display the Helm logo. Within the manifest, we can see some annotations. What we don’t see is the details of the config.json object.
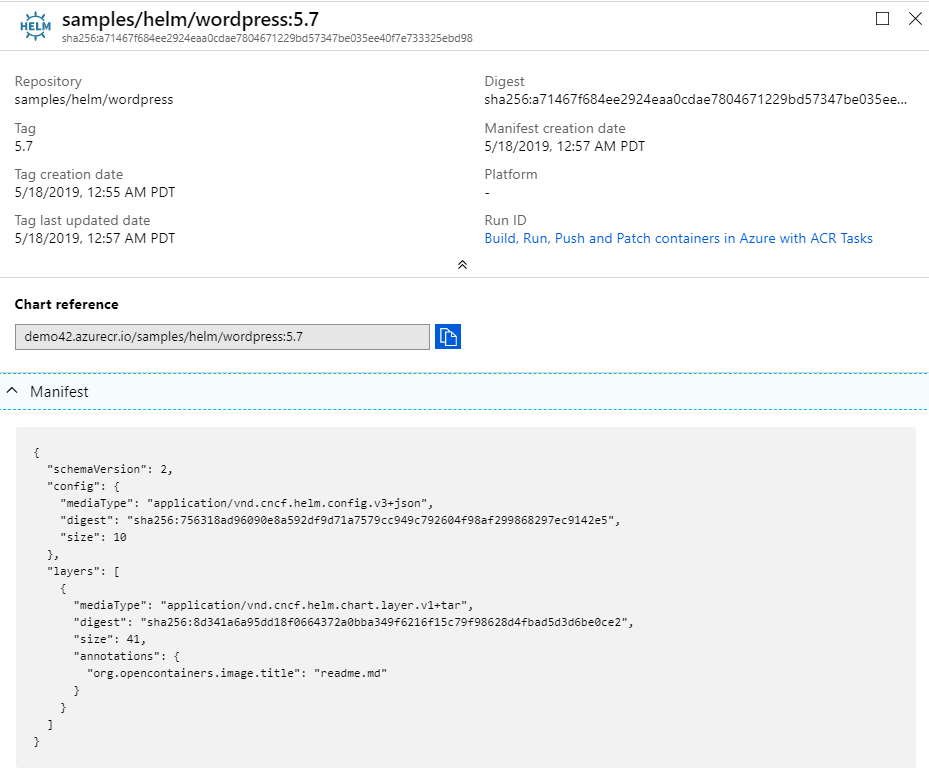
We could display the config.json content, as it is defined as a json object. If we did, it would still be a secondary step, kind of like the [advanced] section of a display.
Versioning of Meta-Data
Did you get everything right, the first time you designed your meta-data? One of the benefits of using a config object is versioning. You can add, delete, even change the names of objects and structures for your versioned config objects. Annotations aren’t versioned, which may be fine for things like description.
Signing Content
How important is the content of these attributes? Do they need to be signed? The config object, as well as layers can be signed. This is also an evolving space, as the current content-trust signing is incomplete as it only signs the digest, not the actual content. And, the signature doesn’t span movement within or across registries. See the Hackmd Cross Registry Signing conversion for more info.
With true content signing, the content of the config.json and each layer can be individually signed. With a new singing solution, you could even sign the collection of layers to be a specific versioned thing. This approach provides the ability to individually sign shared layers across different artifacts, while a specific versioned artifact can be signed as a collection of layers. Most importantly, with a cross registry, signing solution
However, annotations can’t be signed. Actually, as we come up with a true artifact signing solution, where the contents of the layers, manifest and config object are signed, we could assume the manifest could be part of that signing solution. This is an area that still has much iteration.
Private & Public Info
The thing that resonates most to me, is the the about object oriented principals. Keep private information private (custom config), with public information public (annotations).
What do you think?
