In this article I’ll offer a view for why any single new package manager isn’t a great idea, but a generalized artifact package manager is an idea, long in the making.

Cloud Native Evolution
As the industry moves forward with cloud native development, the idea of consuming public content is becoming the norm. The challenge is not if or when someone consumes public content, rather how. The how is encumbered with a breadth of questions from whether the public content can be trusted, to whether it will it be available when it’s needed.
The consumption of public content is neither new, or unique. Users have consumed public content long before cloud native development. Users would download content and host it internally on a shared folder, a website or some other internal location within the users network boundaries. At this point, the user has possession of the content, and isn’t subject to the reliability or security posture of the public content at any future point. The user chooses when to consume updates, with both good and bad side effects. One major difference with cloud native development, is the quick iteration and the assumption that public content can be acquired real-time, from an internal “secured” build system or within a production environment. The best practices and tooling of consuming public content needs to evolve to make the safe and secure decision the easy and default decision.
Consistency Across Artifact Types, Products, Clouds and Services
In the fast-paced, Cloud Native development process, end-users expect products and services to evolve quickly. Developers of products, projects and services are continually being asked to increase the capabilities in a shorter amount of time.
To facilitate faster development and deployment, new projects and products surface each month, often with a new artifact type. Helm, OPA, WASM, Nydus, SCIM, GitOps, SBoM (SPDX, CycloneDX), Security Scan Results (CVRF) are just a sampling of new artifact types. For each new artifact type, should the artifact authors have to think about how they’ll store, discover and distribute their artifacts? Should the artifact development teams have to incorporate how they’ll provide the increasing number of compliance requirements in these new package manager services? Is there a private version, which can be hosted locally? Will cloud service providers be expected to host these services? Would users be willing to pay for these services? Is the user expected to manage each of these individual services with varying degrees of capabilities, configuration and support?
Generalized Artifact Registries
There’s a long list of ever increasing requirements to be placed on package managers. Whether an artifact author should have to build one, or figure out how to enable it in an existing one is just one challenge.
Are package managers a differentiator?
Can the industry benefit from standards where most new artifact types could be stored in a generalized artifact registry?
Will the industry benefit from commoditizing core package manager capabilities into Artifact Services?
Package managers commodities:
-
- REST API for content negotiation and discovery
- Data api for upload and download
- An auth provider, at the minimum for upload
- Metadata services, providing initial and additive information
- Signing of artifacts, providing integrity, as attested to be a given entity, as content is copied within and across registries
We then get into optional commodity capabilities, based on the size and scale:
- Caching for high-volume requests
- Lifecycle management, enabling a user to manage the content stored and purged
There’s a third category, where implementations may differentiate, with the possibility that these capabilities move into the commodity category:
- Diagnostics and logging
- In-region redundancy, geo-replication for locality
Git and Distribution
git became the standard for managing source code and other source files. The industry benefited from these standards, and a new suite of products and services were built atop the git standard. There are a set of scenarios relating to git which differ from distributing packages of content, so there is a realization that git and distribution would co-exist.
To breakup the end to end workflows:
- Creation of content (using git based systems), which pulls content from distributed content
- Distribution of content (using Artifacts Services)
- Consumption of content using artifact specific tooling, over common Artifact Services
Benefits of Standardizing on Registry APIs
Telecommunications and power systems were hampered with competing standards. Just as git up-leveled the creation of content, by commoditizing Artifact Registries, the industry can up-level the distribution of artifacts and the security and reliability capabilities.
- Standard tooling for pushing, discovering, pulling content across registries. Users could easily copy graphs of content, including container images, signatures, SBoM, security scan results, and signatures for each item in the graph from public registries to private, and within and across their internal systems
- Standard browsing experiences for discovering and promoting content in a registry.
- Standards for synchronizing content across registries can be incubated atop a core set of standard apis
- GitOps/RegOps tooling could monitor content in a registry, updating deployments as needed
- An ecosystem of new artifacts will evolve as artifact authors may focus on the value of their artifact type, not how users will push, discover, pull them
- Security scanners can work with a standard set of eventing APIs for discovering new content based on an
artifactType, and focus investments for scanning the new types of artifacts - Users will have fewer products to manage, making it easier to secure their environments
- Cloud providers and products can up-level the capabilities they provide, enabling users to focus higher in the stack of capabilities they must provide to their users
- Lifecycle Management could be easier to manage if users could add meta-data for the intended expiration policy
Are the Registry APIs Complete
In a word, nope. OCI Artifacts effort was started in early 2018, with OCI Artifacts being announced in Sept 2019. It first formalized a means to store additional artifact types in OCI Distribution spec based registries. Storing supply chain reference types are the latest addition, but there are many more, beyond the capabilities listed above. These may include transparency log extensions, or other capabilities.
The question could be phrased:
What is needed in addition to the artifact registry, rather than building yet another way to push, discover, pull distribution artifacts?
The Road to OCI Artifacts
The background to OCI artifacts is a journey that may have some relevance as to how these generalizations are evolving.
In September of 2018, Azure Container Registry (ACR) announced a public preview of Helm Chart Repository support. The premise was to provide the broad set of performance, security and reliability capabilities for ACR container images to Helm Repositories. Before the ACR service team could complete the work, CNAB was evolving, and we engaged the Singularity team to discuss storing Singularity images in registries. The initial ACR Helm support was implemented through an az acr helm sub-command. We then considered what adding support for CNAB, Singularity and other types would look like. Was the az acr command going to explode with a long list ac acr helm, az acr cnab, az acr singularity commands? We quickly realized this didn’t scale.
Success was defined as enabling artifact authors the ability to succeed with pushing, discovering, pulling their artifact type without us needing to be involved.
We also realized this wasn’t a feature we saw value in uniquely providing for Azure. The ability to securely, reliably store, discover and pull artifacts isn’t a differentiator for cloud providers. It’s core infrastructure to enable users on the larger services. The more generic and consistent we can make storing, discovering and distributing artifacts, the more developers could focus on their artifact type capabilities.
We considered what it would take for the various artifact types to support push, discover, pull. Should each registry provide some plug-in to enable each cloud and product registry? We’ve seen the various docker authentication plug-ins and the challenges users face. The best way we could enable all artifact types to implement push, discover, pull would be to provide a standard that all cloud providers and projects would be willing to support.
Docker Registry and OCI Distribution Primitives
To the credit of Docker Inc, Solomon Hykes and the many developers that created the end to end experiences around building, distributing, consuming containers, they recognized the need to have a registry as a core experience. One of the biggest gaps in the Virtual Machine (VM) experience was the common way to find “base images” to add functionality to. The experience didn’t just include content discovery, but optimizations around the size of container images, and the nature of pushing and pulling content across the internet.
Container registries implement a core set of primitives:
- A naming and versioning scheme to identify a container image through a
/namespace/repo:tag - A manifest that describes the container image, which is associated with a
/namespace/repo:tag - A collection of blobs that represent the content of a container image
- A content addressable means to discover the manifests and blobs
There are many more details to these core concepts, but these fundamentals enable:
- Storing any file based artifact from a small single 1kb files, to gigabyte sub-collections of files as a
/namespace/repo:tag - Querying a registry to discover if the
/namespace/repo:tag - De-duping blobs that may be shared across artifacts, reducing the content a registry stores
- Caching blobs on a node, reducing the pull/decompression time
- Immutability of the manifest and blobs to geo-replicate across multiple locations without contention
All cloud providers were already implementing the distribution-spec apis, so why not simply build and extend the experiences around these apis, enabling artifact authors the ability to push, discover, pull their artifacts without having to build Yet Another Storage Solution?
Uniquely Identifying Artifact Types
Similar to other package managers, registries were singularly built to store container images. You could imagine a container version of the Model T quote and say; “You can store any artifact in a container registry as long as it looks like a container image”. Which is exactly what users did. Just as users would rename binaries as .txt or .zip files to send email attachments that wouldn’t get blocked by email scanners, users were stuffing VM images and other artifact types in their registry. They were just making them look like container images.
So, what’s the problem with making everything look like a container image? When everything looks like a container image, how do workflows optimize around unique artifact type decisions? Can a container image security scanner analyze a helm chart for security vulnerabilities? Can a build pipeline trigger a deployment of a helm chart if it doesn’t know if the /repo:tag is a helm chart without first pulling it? Can an end user, or automation cleanup resources in a registry if it doesn’t understand the type? When a container host is requested to run a /repo:tag named artifact, should it pull the artifact only to fail as it’s a video snippet, not a container image?
Looking at filesystems, the file extension is used to differentiate the type. The type is used to provide user feedback when browsing content. Security scanners scan content based on the extension and applications pre-filter content they may open based on the extensions they support.
To minimize the impact to the distribution and image-specs, and to give time to validate storing other artifacts in a registry was a valid scenario, the group agreed to utilize the oci.image.manifest.config.mediaType as a unique differentiator. This is captured in the OCI Artifacts authors guide.

ORAS was Born
Over the holidays of 2018/2019, Josh Dolitsky (the creator of Helm Chart Museum) and Shiwei Zhang (ACR engineering) incubated a set of libraries and a cli for generically pushing and pulling artifacts to a registry using the standard OCI Distribution APIs. Josh creatively named this ORAS, OCI Registry As Storage. The ORAS libraries were incorporated into the Helm CLI enabling one of the first OCI Artifact types. The Singularity team built singularity push and singularity pull to leverage users existing registries. Additional projects like CNAB, OPA, WASM and others have followed suit, leveraging registries as their package manager.
The combination of a common service API and a set of libraries to interact with those APIs fostered a growth in artifact types that can be used from development through production.
Notary v2 Incubates Reference Types
-
As the Notary v2 working group identified core requirements, we recognized the need to store detachable signatures. This had multiple benefits to Notary v2 signatures, such as avoiding trojan horse attacks, to supporting multiple signatures without impacting the original unique digests of the subject artifact.
It turned out reference types weren’t unique to Notary signatures, and other secure supply chain artifacts would benefit as well, such as SBoMs, security scanner results and other signature formats.
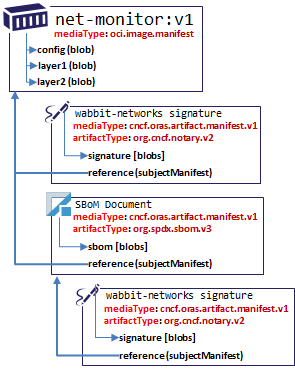
To address this reality, the reference types were refactored out of the Notary v2 project, and proposed through a few PRs to OCI Artifacts:
- OCI Artifact Manifest – with weak reference support #27
- OCI artifact manifest, Phase 1-Reference Types #29
The Artifact Reference Type working group has been working under the ORAS Project while the OCI formalizes the OCI Working Group process.
But Wait, There’s More
You may have noticed I called out push, discover, pull as core APIs. It turns out discover is a common API on package managers where users can search for a set of packages that match some criteria. While the docker client has docker search, it’s unique to docker hub search.
There are many other capabilities missing from the distribution-spec which I wrote about in an August 2019 Blog post: OCI Artifacts and a View of the Future. Since then, the list has evolved:
- Signing – as Docker Content Trust isn’t considered viable
- Metadata – which can be added after an artifact is pushed
- Eventing APIs – to support asynchronous workflows
- Lifecycle Management – providing a means to identify how users can manage the content in their registry
- Dependencies and References – enabling SBOMs, Signatures, Metadata and other artifact types to be associated with a
subjectartifact.
You may ask whether the OCI distribution-spec should cover these types of capabilities, and you wouldn’t be alone.
Today there’s limited cross registry tooling as each registry has implemented variations of the above commands uniquely. If registries were differentiating capabilities of each product, you might argue that’s a reasonable thing. But, are these differentiators? Can we help the industry, developers and end users by creating a set of standards that can be built upon?
Layering and/or Consolidation
To achieve the goals of a vendor-neutral set of apis, libraries and cli, ORAS was donated to CNCF. While ORAS started as a set of libraries and a cli over distribution-spec APIs, following the guidance under OCI Artifacts, it also became the incubation location for the artifacts.manifest which enables storing and discovering cross artifact references,
enabling a graph of secure supply chain artifacts to be stored and signed.
The question remains how will the various projects be converged or possibly layered.
Some options including:
OCI & CNCF
- OCI Distribution-spec maintains low-level APIs
- CNCF oras-project/artifacts-spec maintains the higher level Artifact Registry APIs
- CNCF Distribution implements the reference implementation of the ORAS Artifacts Registry APIs
OCI Consolidation
OCI Artifacts and ORAS Artifacts converge into the OCI Distribution-spec, providing a single place for the Artifact Registry APIs to evolve.
Next Steps
The OCI TOB has been discussing how to form working groups, which was recently merged. The Reference Type Working group is now being considered by the OCI TOB. My personal preference would be to unify the artifact-manifest to store generic artifact types that may reference other artifacts, with the referrers/ api for discovering a graph of artifacts. By incorporating these into the distribution-spec, the refactoring may begin as a standard for distributing artifact types. This puts context to the discussions of lifecycle management and other standards that help foster a growing ecosystem for the common distribution and consumption of content across products and services, enabling a more secure supply chain.
Just as git unified the creation of content, to properly secure content across cloud providers, vendors, products and projects, the industry needs standards for distributing content. While there will be additional capabilities yet to be identified, commoditizing the distribution of content is a step in that direction.
