Last week at build, Scott Hanselman and Scott Hunter presented an ASP.NET Core app we called Where You At. We were quite excited at the response and set of questions that arose. In response, we wanted to write a series of blog posts, each of us covering the different aspects of what we built, why and what we learned.
Where did the demo idea come from and why?
With all the buzz around cloud languages, such as Node.js and GO, we asked ourselves, how can we demonstrate the value of ASP.NET Core as a language to be used everywhere? .NET isn’t just a Microsoft stack, limited to IIS, Windows and Azure. .NET Core can run on the Mac and Linux as well. Scott Hunter, Scott Hanselman and I had been going back and forth on various demo ideas. Hanselman suggested pins on a map. Hunter wanted to get Red Hat involved. I wanted to show multiple containers and the Dev/Ops workflow.
What better way to show ASP.NET Everywhere, but to actually run it everywhere? What if we could run it on all the top clouds including AWS, Google, Docker and of course Azure? Getting the crowd engaged with the map was hook.
The Demo Prototype
Here’s the demo script as we envisioned it
Ask the audience to hit https://aka.ms/WhereYouAt
- They see a page that asks them to submit their location

- Prompted to capture the city only
- Display shows bing maps, with pushpins globally

- As customers start submitting their location, pushpins show up with a flag indicating which cloud processed their request (Azure, AWS, Google, DockerCloud)
- Scott Expands the lower section of the screen showing a view of Azure, Amazon, Google and DockerCloud, all running ASP.NET Linux Containers

- As the system receives requests, we’ll see them allocated to the different cloud providers running another ASP.NET Core Linux images. The images are instanced on demand, round robin across the various cloud providers
- The web page shows:
- Groupings for Azure, AWS, Google, Digital Ocean and Docker
- Number of containers concurrently running in each cloud
- Number of tasks processed
Number of unique users
Container Chaos MonkeyRandomly click the red [x] to kill a containerNotice the system self heals and replaces the container near instantly, including adding to the load balance
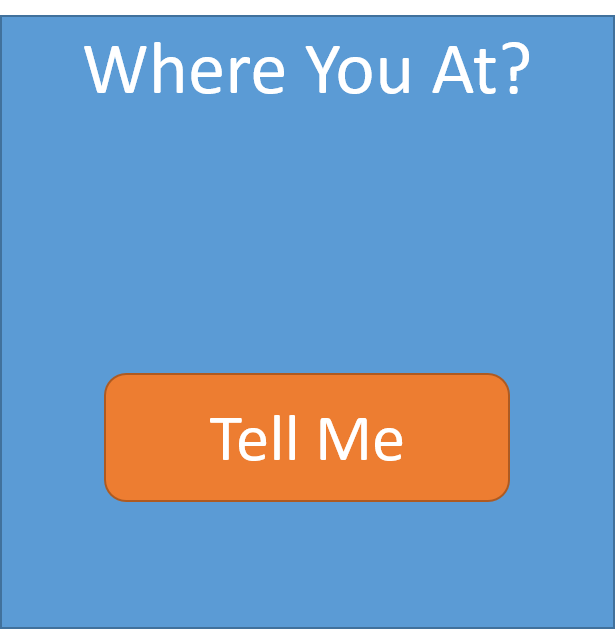


As you can see, we had a prioritized list, with aspirations to play a little container chaos monkey. Scott could randomly kill individual containers, or hosts and the container orchestration systems would self-heal. As it evolved, we ran out of time, but we also recognized the value of container orchestration systems wasn’t the value prop we were trying to take on for this demo.
The Team
- We assembled a team to and outlined what we needed:
- UI
- Services
- Architecture for how this would be deployed
- Development environment including a repo, build system and the set of tools we needed
- Production cloud hosting – the container orchestration systems to host the app
- Load testing, to make sure we didn’t crash and burn in a very visual fireball, just as we’re demonstrating the value of containers and the cloud to achieve scaling
- Our team was initially made up of:
- Scott Hanselman
Load balancing and worked across the board, jumping in to solve problems wherever they came up. Scott has quite the network of people, not the least of which from his Azure Friday channel 9 recordings. - Maria Naggaga Nakanwagi
The user interface, including all HTML, JavaScript and API calls from the client - Glenn Condrom
The API services, including Azure Storage - Steve Lasker
Cloud deployments, containerization and automated VSTS build steps, API services
- Scott Hanselman
The Architecture
Since we wanted to show multiple clouds, we needed a way to load balance across the clouds. Scott Hanselman had done a Friday Azure show on Traffic Manager, which seemed perfect for what we wanted.
Within each cloud, we had aspirations of dynamically scaling the app on demand. This meant docker hosts and container instances would change over time. Each cloud orchestration system has a means of providing dynamic discovery services, so we wanted to take advantage of them within the each cloud. Each cloud would load balance amongst itself, and we’d use Traffic Manager to load balance across the different clouds.
Our diagram looked like this. You’ll notice Docker Cloud has a load balancer as a container. We’ll discuss that in more detail below.
Cloud Specific Deployments
Azure
- Azure Container Service – for container management, using Mesos
- Azure Load Balancer – A nice feature of ACS is the dynamic integration with the Azure Load Balancer using the PaaS layer. This means you can defer the load balancing configuration and reliability to ACS as it dynamically integrates with the Load Balancer. There are inner communications where’ you’ll likely want direct control over a load balancer such as HAProxy or NGinX. However, the front of your cloud, it’s pretty common to use a PaaS load balancer.
AWS
- AWS EC2 Container service – for the container management. We deployed 3 t2 Micro instances running Linux with their standard template.
- AWS EC2 Load Balancer – AWS and Azure container services both share the integration with their PaaS layers.
Docker Cloud
Docker hosts the container management layer in their cloud, while they defer the VM instances to be one of the other public clouds, including AWS, Azure, Digital Ocean and others. Docker is focusing on the docker orchestration services, as opposed to competing with actual hosting services. In this case, I of course chose Azure to host my VMs, which I was able to simply slide the slider for the number of instances.

The Docker Tutorials walked through using HAProxy as a load balancer, deployed within the service definition. This is why you see a load balancer container running within the Docker Cloud. This can be accomplished through any cloud, and is a good example for how you can, and likely would use each configuration.
I had hoped to deploy with Google Kubernetes as well. I had this partially setup, however the Google kubectl api isn’t supported Windows, so changes were always an additional challenge. Many of their APIs require a bash environment. I thought about using the pending Ubuntu on Windows option, but we were running out of time, and I wasn’t intending to do a cloud compete story, so we made a scoping cut. Kubernetes has some great networking features that make service discovery, and container port management simpler, but we just didn’t have the time to do everything.
Automated Builds
As a team making frequent changes, working across the country, on different time zones with different time slices of work, we needed an automated build system.
I had been working with Donovan Brown on our Visual Studio Team System docker integration. He had built some VSTS build steps that worked with ASP.NET Beta 6, but we needed some updates to work with RC1. We also wanted a Docker Compose step to deploy multiple containers for validation before deploying to the various clouds. The Visual Studio Team System Release Management team had been building some Visual Studio Team System Docker Build Steps. This was a great chance to test them out, provide some feedback for how to integrate the Docker Tools for Visual Studio dockerfiles we added to a project, and automate the builds.
Here’s our automated build goals, and where we landed using the preview of Visual Studio Team System Docker Extension:
- As code was checked into https://github.com/shanselman/aspneteverywheredemo automate the build

- Build a docker image to another Linux VM named AzureBuild

- The Linux VM was provisioned with a pre-release version of the Azure Driver for Docker-Machine. This simplifies the configuration and provides Azure ARM based VM configurations, and port provisioning
- We considered running Docker on the build agent, but wound up using separate Linux VMs
- The dockerfile is nested in the Docker sub folder, and it’s the .release version. As scaffolded by the Docker Tools for Visual Studio
- The Image name uses my registry hive, with the project name and the $(Build.BuildNumber) VSTS Variables
- The Docker Context is set to the root of the project to capture the .dockerignore file, and have the correct context for adding files to the image
- The working directory was left as the default

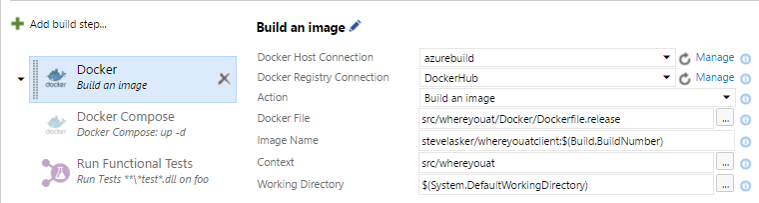
- Compose up the collection of images for testing
- This turned out to be more problematic. We ran into issues where the previous containers were still running. As it turned out, the demo only utilized a single container, so we punted this for now. We’ll work on fixing compose to support docker-compose kill scenarios, including having the previous version of the compose file.
- Test the image(s)
- We took the common shortcut, and didn’t write tests. This bit us several times, see below for lessons learned.
- If tests complete, push the image to the registry, as versioned with a build number
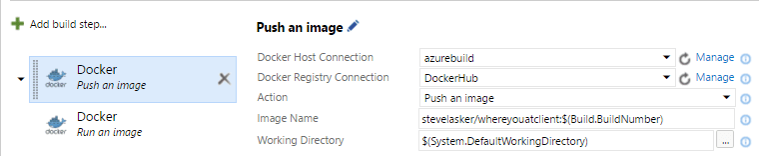
- Using the same docker build VM (azurebuild)
- Pushed the image, using the $(Build.BuildNumber) tag

- Push the image to a staging server, that always has the last built image running for manual validation
- This should have been compose as well, but we only had the one image
- The host is another Linux VM w/Docker, provisioned with docker-machine to avoid conflicts with the CI build docker host
- Because this went to another host, we had to first push to the registry, so we could pull to this secondary host. In a container workflow, once you build an image, you use that same image. Rebuilding the image introduces the possibility of differences to surface.
- Image name uses the $(Build.BuildNumber)
- Set the container name to our project
- Set the ports to 80:80, otherwise the container would not be accessible through the host
- With the current Docker Tools for Visual Studio, we must set the environment variables. This will change as this shouldn’t be required to simply run a dockerfile
- Tag the image latest

- Using the same host that we pushed for staging, although we could have used the build host as well
- Uses the generic, Run a Docker command action
- Tags the image from our build number to latest
- Push the latest image to the registry

- Uses the Docker build step, with the Push an image action
- Uses the same host that we tagged latest. This is important as until we push the image somewhere, the only place that image exists as tagged is the same host. You can see this with the docker images command
- References the latest tag. Since the only thing we’ve changed is the tag, you’ll notice the push goes super-fast. Docker is smart enough to know the images layers haven’t changed, and it just tells the registry to update the latest tag to the same layers of our image with the latest build number

- Automate the various clouds to re-deploy the latest image(s)

- In full transparency, this was another fail, and we just didn’t have the time to “do it right”. While Mesos and Marathon have great REST APIs, the March 2016 implementation of ACS requires SSH tunneling. We tried a quick hack to tell Marathon to re-deploy the app, using the latest tag. This didn’t always work, so we disabled it.

Configuring the Docker Steps
Configuring the actual docker steps was quite easy. The VSTS RM team has done a great job providing help with the ?’s next to each control. Being able to copy/paste the contents of the cert files from the docker-machine sub directory was pretty straight forward.
Configuring the build agent to work with Docker was a bit tedious as it needed a number of dependencies, such as Node, NPM and bash. We discussed various options, such as a pre-configured hosted service. However, we also know that developers use various configurations, and may depend on specific versions of the docker client. For now, we’re focusing on custom build agents. But, something we brainstormed a bit was a shared container build system, where you’d provide VSTS a build image, which we’d provide a base image. There’s more to imagine here, but we certainly didn’t have time for build, so the idea is on our backlog for now, and we just worked through the installation steps.
We’ll document configuring a Docker Build agent in another post.
Docker Registry (hub)
A key aspect of any container workflow is a Docker Registry. It’s your repo for images. In the container workflow, you don’t deploy code, you deploy validated images. In most cases, you’ll likely want to deploy a private registry, close to your container orchestration system. For instance, AWS has a private docker registry, but only in their east coast data center. Azure ACS will soon have private registry support as well, without having to stand it up as a container.
Since we were deploying the app across multiple clouds, and we were perfectly fine having our images available to the public, we used docker hub for our whereyouat image. You can see the various images, including the VSTS build number as tags. Yup, we had 157 builds to complete this demo, and that’s only because we didn’t always have automated CI configured. …because we never wrote tests and didn’t want to break our deployed app.
The Development Environment
Our development machines were:
- Windows with Visual Studio 2015, although Glenn sometimes worked on his Mac with VSCode
- Docker Tools for Visual Studio
- Docker for Windows Beta
- Git and/or GitHub
The project evolved
- We started off with the standard ASP.NET RC1 empty project template LadyNaggaga (Maria) added
- Glenn optimized the project to supporting just the CoreCLR. This reduced our image size, and improved our docker build times as we needed fewer nugets. It also exposed a hidden issue that DotNetWatch, used for the Edit & Refresh docker scenarios only works with dnx451.
- Glenn added some locations API as well as the first bit of TableStorage
- I added the Docker Support which scaffolds out the various dockerfiles used to containerize the app.
- Changed from using port 5000 on the container, and port 80 on the host, to simply using port 80 on both. Since the containers aren’t competing with IIS or IISExpress, it’s easier to just configure these to port 80. We’ll be changing the default in release 0.20 of the Docker Tools for Visual Studio
- Glenn added a settings class to retrieve the Cloud_Name and other values set with Environment Variables
- Maria added the push pins
- Scott had his first ahh haa moment for why we test code in a container before checking it in as we stumbled upon the dreaded “works on my machine”, but no in the cloud issue, which was a simple case sensitivity issue, but we wrestled with Git on Windows as it didn’t see the file changed because Windows doesn’t care about Index and index
- I added the counts API, and had to revive my LINQ GroupBy query syntax skills, wishing we using SQL with TSQL and a server side query processor so we didn’t have to pull all the data locally
- I added the Load Testing APIs, with random lat/long data that I didn’t really care the randomness looked like an asteroid soaring through the sky
- Scott and I realizing our scalability problems weren’t related to how we were load balancng across the clouds, but rather we were only bringing back the first 1,000 rows from Azure Storage
- Put some safeties in, limiting the total results to 20k rows. That should be enough, right? Hmmm, don’t underestimate the Hanselman possy. Or, the fact that we didn’t limit users from constantly clicking the “tell me” button
- Brute force disabled the APIs as people kept hitting the site, and we’re now only showing AWS as the cloud serving all the requests, because AWS comes before Azure, and we limited the total row count to 20k
Global Testing
To see how well this was working, and if Traffic Manager was going to route traffic appropriately, we needed some global testing. We asked the Docker development team we’ve been working on who work across several locations, including Paris, Barcelona and San Francisco
We asked the Microsoft Regional Directors to tell us WhereYouAt, and got a breadth of coverage. Including an instance in the middle of the ocean Blake Helms predicted a container ship. This was our first true validation, and we were feeling better about the distributions

Load testing a cloud deployment
We knew we had to load test this thing, or we were destined for failure. We knew there were lots of tools out there, but where to start? Anytime you scope load testing, you need to start with your lower and upper bounds of what you hope to prove. When I asked Scott how many people he figured, we assumed 1,500 in the room. And a maybe a few thousand watching online. So, we estimated around 5,000 users.
What we thought of:
- Users will come from around the world
- Load test serving pages to thousands of concurrent users
- Load test writing to Azure Storage concurrently
- Pulling thousands of map points to load the bing map
- Our app used JavaScript to get the lat/long location, which wasn’t as easy as testing from a load balancer
- We need an API that generates a random lat/long that can be called with a simple GET API call
- How would load be distributed, and would we accidently make AWS look much better than Azure ACS
What we didn’t think of/realize:
- Traffic Manager is highly efficient at picking the most performant node in its list for routing, based on where the user is coming from
- Traffic Manager is sticky, and integrates with DNS so the client doesn’t need to request a route from Traffic Manager each time the same client makes a request
- If you run a load test from the same machine, Traffic Manager won’t send traffic to the various nodes
- We need to run tests from various regions to see how it would perform
- Where I happened to deploy the various Docker Host Instances across the various clouds would have an impact on where Traffic Manager routed request
- I chose East US for AWS as it was the only location AWS hosts a private Docker registry – although I didn’t use it
- I chose West US for ACS, as it’s close to where I’m working – Redmond
- I chose Central US for Docker – ummm, I don’t remember why. It might have been the default
- If you don’t implement Random correctly, you can get an interesting plot of points.

- Azure Storage returns just 1,000 rows by default. And, if you hash by Cloud_Name, you can get skewed results as only the first thousand rows are returned, which might just happen to be AWS – as AWS comes before Azure.
- If you fix the random generator, and run load tests for long periods of time, each request is written to Azure Storage, and when you request “all points”, that the map can fill up quickly. This is what I called global coverage:



We needed real help with Load Testing – bring in the experts
As we got closer to the demo, (two nights before the demo, in the lobby of the hotel around 10pm), Scott(s) and I realized we still hadn’t load tested this thing to our comfort. Scott Hunter offered the ASP.NET Performance team’s assistance. Sajay Antony and Siva Garudayagari jumped in and asked what they could do to help. They’re also writing up their posts, coming soon.
The Results
As you likely saw, the demo went pretty smoothly. We collaboratively predicted most of the embarrassing failure points, and didn’t crash and burn. At least not during the demo.


Why did AWS get more hits?
We debated showing the actual results. What might someone infer from this data? Was there anything to deduct from this? Should someone conclude some sort of cloud shoot out? The answer is yes, there is something to deduce, as there always is, but it wasn’t a cloud performance comparison as we didn’t optimize anything. In fact, my initial attempt to be equal may have skewed the results.
We haven’t yet drilled deep into the data. But, we wanted to be transparent, as there’s always something to learn.
My working theory is this. If you look at the map, I just happened to provision AWS on the east coast.

Just a quick comparison to the results map shows the majority of traffic came from the east US, and Europe. I just wasn’t thinking globally when deploying the docker hosts, and under estimated the breadth of the Hanselman Possy. We may do this demo again, and will definitely take into account the global presence, not to mention the global footprint we can provide with Azure.
Lessons Learned
- Real user testing is required to get real results. Automate what you already know, but personal interaction is required
- Having a few friends and family test earlier in the week, gave us the confidence the load balancer was working as expected. Having the RDs test it the day of verified we weren’t going to flop on our face
- If you want to create random points across the globe, you can’t just instance a new Random object each time. See Scotts fix here
- We still make mistakes with checking in secrets. While we knew didn’t want to check-in the Azure Storage key, we needed it during development. ASP.NET has a feature for setting environment variables, but the value is stored in your launchSettings.json file, which is a project file. As I fixed a case sensitivity issue, I accidently checked in the launchSettings.json file. I reverted it, but I had to go back and change the key, and ask the rest of the team to change their keys as well.
- ASP.NET Core has a secret management feature, but you have to know to look for it, and I shouldn’t just use the shiny thing in the properties window that looked like the right feature
- Action Item: Even if we built a feature to store environment settings per user, and didn’t check them in by default, environment variables are not secure when using Docker Containers, and it’s recommended to use alternative solutions, such as KeyVaults. For our Docker Tools for VS, I’ve added KeyVault integration so we can help you, and us, do the right thing by default.
- Testing in a container is key, even for simple fixes
- There are lots of differences between Linux and Windows. Even Windows Client and Server are different. I caught a change for the final map, and while I fixed the file name with a simple VS auto-complete gesture, I was too rushed and didn’t bother to test this in the container before checking in. And, I didn’t notice the Map folder name was also not cased properly.
- Edit & Refresh would have been really helpful, and we need to get it fixed for .NET Core in RC2
- We should have limited the users to submitting one location
- We should have implemented telemetry with App Insights to see more information regarding where users were coming from and who was hitting our super-secret APIs
- We need to fix DotNetWatch to work with the Core CLR for Edit & Refresh with ASP.NET RC2
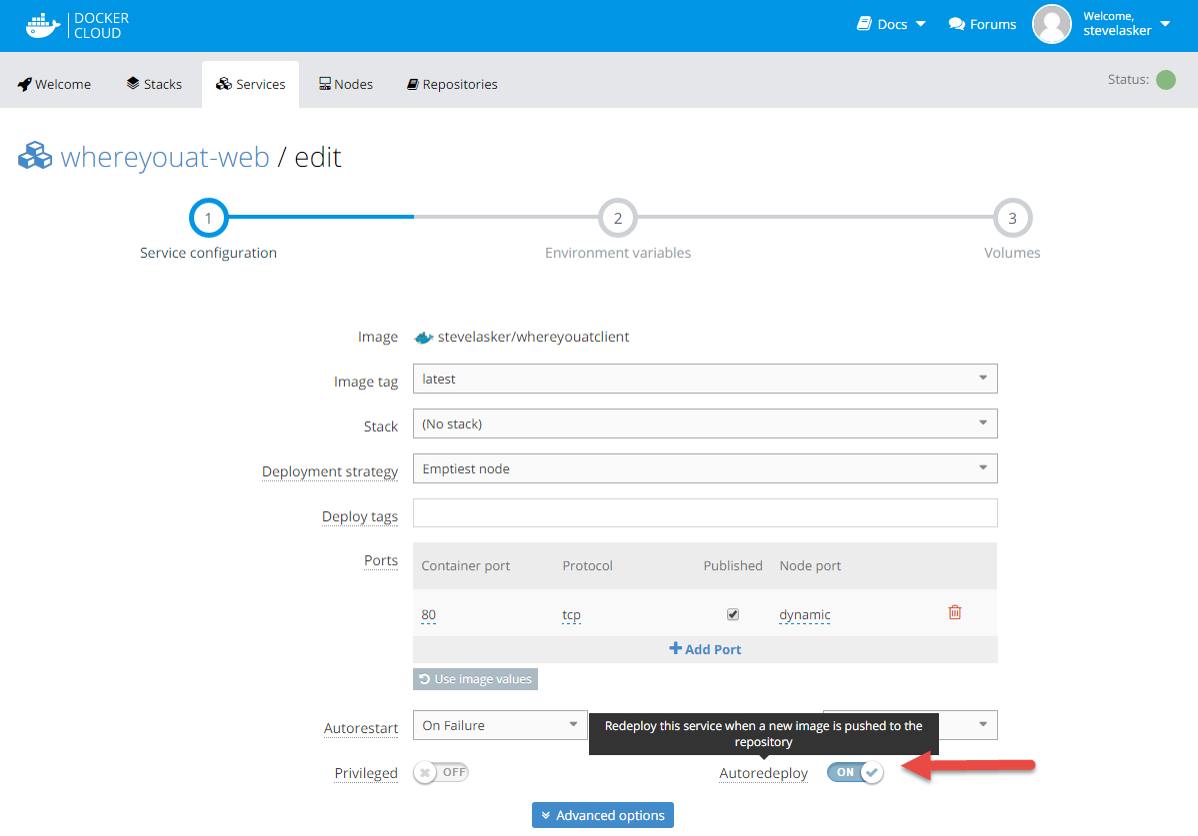
- Automation will save you time, if you invest the time:
- We prioritized the automated Docker Builds with the Docker Tools for VSTS extension, as it’s part of the e2e scenarios we were targeting at //build. I deferred the automated deployments to Azure ACS and AWS as it was going to take some extra work that I didn’t think I had time to do. Docker Cloud was able to hook the registry. Generally speaking, I wouldn’t suggest this approach in production, unless you’re deploying a single container. If you only put containers in the registry that have been validated, and/or you only tag it latest if it’s valid, you can be ok, as we were for this demo. However, if you’re application is made up of several images, you’ll want to test the collection of images before pushing an update, or individual image pushes may destabilize your container deployed solution

- Action Item: Work on automated deployments from VSTS to various clouds, so we can help you do the right thing, deploy an update after your tests are complete. Not, just hook registry updates.
- We prioritized the automated Docker Builds with the Docker Tools for VSTS extension, as it’s part of the e2e scenarios we were targeting at //build. I deferred the automated deployments to Azure ACS and AWS as it was going to take some extra work that I didn’t think I had time to do. Docker Cloud was able to hook the registry. Generally speaking, I wouldn’t suggest this approach in production, unless you’re deploying a single container. If you only put containers in the registry that have been validated, and/or you only tag it latest if it’s valid, you can be ok, as we were for this demo. However, if you’re application is made up of several images, you’ll want to test the collection of images before pushing an update, or individual image pushes may destabilize your container deployed solution
- Nothing beats trying it out
- I’ve been working on docker tools since last summer, and it’s been a blast. I’ve talked to many customers trying to get their head around docker, startups that have been using docker in production for 18 months and enterprises that have worked through the critical security reviews.
- I’ve deployed a number of apps to single docker hosts, and even some demos to Azure ACS, Amazon Container Service, Google Kubernetees and Docker Cloud. However, I hadn’t yet lived the life of a real app life cycle.
- Until you really walk in the footsteps of your customer, or the scenario you wish to deploy, you just don’t what you don’t know.
- Build an app. Deploy it to the cloud. Understand the Dev/Ops lifecycle, and don’t just assume someone on the Ops side will pick it up and figure it out.
- Attempt to implement best practices. When you can’t; don’t get blocked. Hack something to keep moving forward. Take a note, and come back later when you’ve learned more about the total scope of problems you’re facing.
- Have real customers try it out.
- Understand your user distribution, load and list what you know might fail, and watch for things you might not know will fail.
- Live it, learn it, rinse, repeat.
References:
- Docker Overview deck presented at VSLive Las Vegas
- Docker Tools for Visual Studio – scaffolding of docker assets to your ASP.NET Core project. Edit & Refresh, with breakpoint debugging coming in the 0.20 release
- Visual Studio Team Services – Docker Build Extension – Docker based CI/CD
- Docker for Windows Beta – replacement to Docker Toolbox, including the replacement of VirtualBox. See more info here.
- WhereYouAt SourceCode – on GitHub
- Azure Container Service – for container orchestration using Mesos and Marathon
- Docker Cloud – for container orchestration using Docker & Swarm
- AWS Container Service – for container orchestration using AWS
We had a lot of fun building this demo, and we’ve learned a lot to improve the product.
What have you learned? What would you like to see? What are your biggest pain points?
Please give the Docker Tools a try, and please do give us the feedback
Most of all, thanks for your interest in the work we love to do
Steve
